笔记软件选择问题:回归记笔记的本质
(可收听播客)
前言
这几年新型笔记软件在互联网上掀起了不大不小的涟漪。新型笔记软件仍然是小众事物。在大多数人那里,OneNote、印象笔记甚至 Word 仍然是他们对笔记软件的一般设想。新型笔记软件的实质是一种新型电子玩具。折腾新型笔记软件,就像沉迷电子游戏一样,无非是换一种娱乐方式。
过去几年我选择了 Roam Research(以下简称 Roam ),甚至在上面完成了我的博士论文的全文撰写。不过,今天我不得不重新考虑这件事。和博客一样,折腾笔记软件浪费了我大量的时间,甚至可以说耽误了我的学业。如今,我又沉溺于电子游戏。笔记软件、博客和电子游戏,真可谓互联网三大电子玩具1,我一个也没落下。在这个过程中,我有许多故事可以分享。现在,我希望做一个有关笔记软件选择问题的终章。
在这篇文章中,依照我对记笔记这件事的本质的理解,我将逐个点评各类新型笔记软件,并且给出选择它们的建议。当然,文章的重点不在于详细介绍和对比各类软件的特性。
两个最重要的问题
笔记是我们最重要的资产之一。持久性问题是选择笔记软件需要考虑的核心问题。选择一种笔记软件,等于选择某种记笔记的方式,加上技术上的原因,不要期待将来可以无损迁移数据,所以必须慎之又慎。我们必须考虑,十年之后,我们的笔记将何去何从。新型笔记软件之间不可能做到无损迁移。为了尽可能保证较好的可迁移性,尽可能选择纯文本形式保存的笔记软件,以确保将来的笔记能够被正常读取和搜索。
还有一个问题值得考虑,那就是利用 AI 技术的可能性。两年前,我曾经在 Reddit 看到有人评论,Roam 的前途取决于其对 AI 技术的利用。当时我不以为意。自己记录和整理的笔记,为何要依赖 AI ?然而 chatGPT 的出现,改变了我的想法。未来一两年,没有 AI 技术加持的笔记软件,将会被淘汰。将来,笔记软件要么自带要么允许用户自行接入某种 AI 模型。比如,用户可以在自己的电脑上安装某种 LLM ,读取和分析自己的笔记数据,实现与 AI 模型对话的能力。随着笔记数据的膨胀,以及 AI 模型的改进,计算机在某些方面比我们自己的大脑还会处理我们的笔记,是显而易见的。
Roam Research
目前,我的主力笔记软件仍是 Roam 。不过,经过几年的使用和思考,我一直在犹豫是否放弃它。 迁移笔记从 2023 年开始就是我的一个纠结项目。
如今看来,Roam 可能是最不长远的新型笔记软件。它已经进入了小修小补的维护阶段。无论是开发者还是用户,都对这款软件失去了曾经的狂热。可以看到许多寻找 Roam 替代品的帖子。考虑到其昂贵的价格、乏善的交流渠道、与日俱增的竞争对手,这款笔记软件很难走得长远。第一批 5 年“信徒”计划用户即将到期,不知道续期的比例如何,如果不好的话,Roam 将面临糟糕的财务问题。这加剧了不确定性。
我用Roam写完了自己的博士论文(将来可能会介绍一下2)。Roam 最重要的优点,在我看来,有以下几个方面:
-
大纲编辑器。这对于有条理的梳理和写作是相当重要的。相信我,就笔记软件而言,认识了大纲编辑器,就不要回到平文本编辑器了。此外,Roam 的编辑器性能非常好。
-
导出功能。用大纲编辑器撰写的文章,可以轻松导出普通的 Markdown 文件,用于其他用途。与之相比,Logseq 尽管可以导出平 Markdown 文本,但在行与行之间缺乏空行,导致其所导出的文本在普通 Markdown 编辑器无法正确识别段落,难以利用。我目前没有找到比 Roam 更好的大纲编辑器。
-
有颗粒度的双链。这一点是众所周知的,无需赘言。在后面我会对此提出新的评论。
-
优雅的UX。Roam 各种 UX 设计,是创造性的。使用 Roam 做笔记,就像在写网页一样,彻底摆脱了以文档为中心的传统电子笔记组织方式。
尽管如此,我仍决定放弃使用 Roam。这也有几个原因:
-
收费过于昂贵。这不仅阻止了用户,也影响了它的寿命。 Roam 已经无法给人们们提供长久的信心。Reddit 上不断有人问,“Roam 死了吗?”
-
开发陷入停滞。没有迹象表明,将来能够在 Roam 中充分利用 AI 技术。
-
搜索功能孱弱。使用 Roam 记笔记是非常愉快的,但每次写文章搜索资料却很痛苦。目前没有任何迹象表明,Roam 的开发者意识到了这个问题。
-
块引用双链并没有那么重要。这些年的实践表明,块引用双向连接没有达到预期的效果。我们其实没有什么时间回顾这些链接。最实用还是是页面引用链接,也就是使用
[[]]添加的链接。它们使我们彻底摆脱了笔记的传统组织方式,并使得记笔记像建设网站,阅读笔记像浏览网站那样。 -
编辑器的稳定性问题。Roam 的编辑器性能一直很好。偶尔出现问题,经过反馈,也能及时修复。然而,最近几个月,中文输入又出问题了。在打中文时,经常出现直接键入字母而不是汉字的问题。之前,由于 Roam 有相当数量的中文用户,会有不少人会反映问题。而现在,Roam 的中文用户可能寥寥无几了吧。可能也正因于此,中文输入的问题久久不被注意和修复。
-
可迁移性太差。如果使用 Roam 做了很多块引用,将来的迁移数据成为可怕的事情。不可能有无损的迁移方案。将来你的笔记将充满一堆
((8g_o_giEe))之类的字符串。使用 Roam 的方法建立的笔记体系,可能一朝化为乌有。 -
前景不明。任何软件都有终结的一天,或早或晚。Roam 需要登录才能访问自己的数据,让人不禁担忧。尽管官方也考虑过,当 Roam 终结时,以某种方式为其续命,比如开放源代码,但他们现在不愿意做出任何此类承诺。
总之,Roam 的前途是渺茫的。Roam 在国内的著名鼓吹者王树义老师,也放弃了Roam,转投 Tana3。 提供的核心功能不是必须的。4
回到笔记的本质
经过这几年的实践,我最重要的一个体会是,应该回到记笔记的本质:记录和检索。信息技术使记笔记比以往任何时候都更容易,当需要时,也比任何时候都更容易检索。记笔记的日常是,在 Word 程序或纯文本编辑器中写下你的笔记,在将来的某一天检索其中的片段。我们平时根本没有时间浏览和回顾笔记,特别是在经年累月之后。
当然,我不否认应该追求更多的便利。然而,如果一款笔记软件两者其一做得不好,就可能存在致命的缺陷。前面提到,Roam 的检索功能是令人抓狂的,有人形容,每次在 Roam 中搜索,就像面对一个巨大的黑箱。在 Roam 的搜索框搜索关键词,只能一点点的往下滑动寻找。你无法在页面之间筛选,这也意味着你无法快速定位。说实在的是,Roam 的搜索功能甚至不如 Windows 的资源管理器的。假如你在 Word 上记笔记,你的笔记文档都放在一个文件夹里,你可以在资源管理器上搜索关键词,而资源管理器则会返回带有关键词的各个文档的列表。这个操作在印象笔记中也很平常,但在 Roam 中却令人抓狂。
与之相对照,Obsidian 的搜索功能是我目前看到的新型笔记软件中最好的。最重要的是,它可以帮助我们快速定位页面或者说文档。
如图所示,在行中搜索关键词“规范 情感”,然后选择折叠搜索结果,我可以快速定位页面。由于所有的 Obsidian 数据本身就是纯文本的Markdown 文件,这一展示方式是顺理成章的。
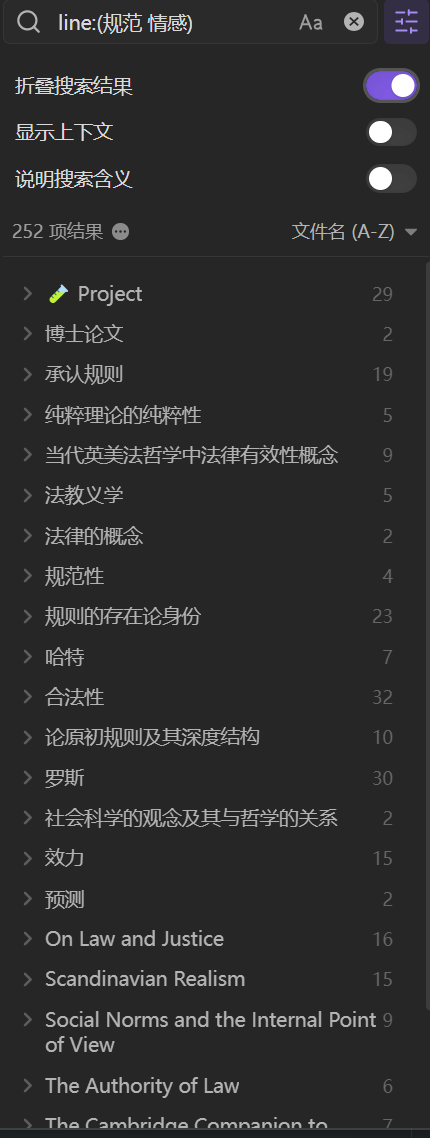
与之相对照的是 Roam 的搜索体验。
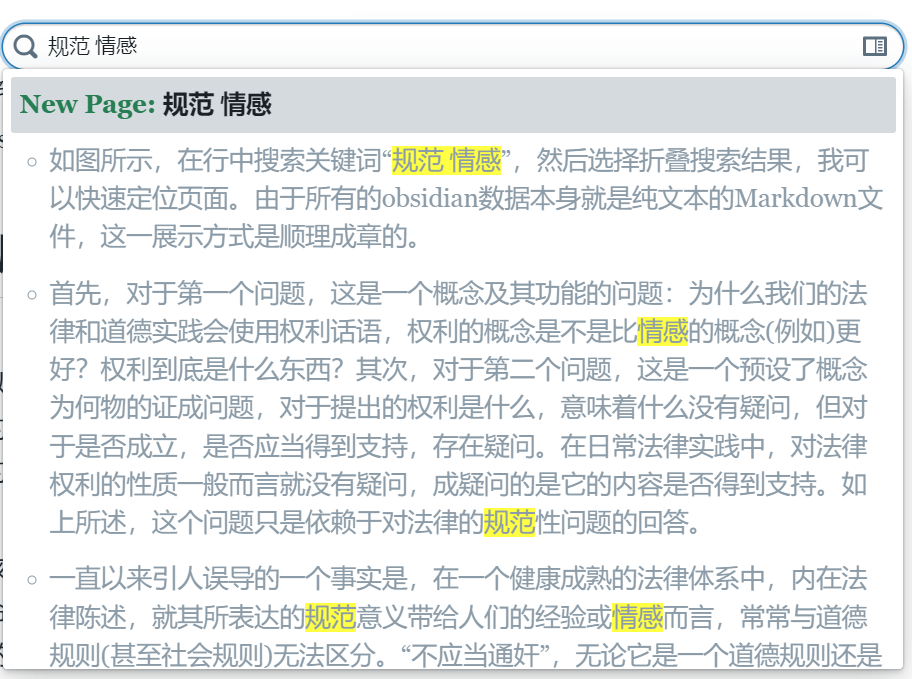
此外,Roam 提供的 “Search+” 插件也并不提供页面折叠功能,其本身提供的高阶块搜索也是如此。
我认为,在记录和检索之外,笔记软件提供的其他功能仅是锦上添花。不要把简单的事情复杂化。这也是为什么说,新型笔记软实质是一种特殊的电子游戏。
时至今日,似乎 Roam 开发者也意识到在 Roam 中搜索的困难,不断改进 Roam 的 qury 查询。这个查询逻辑和条件是在太复杂了,需要投入一定的精力学习,一般人根本没有耐心。我至今不知道怎么做。
不过,值得称赞的是,第三方插件使得 Roam 中的搜索提价得到了巨大提升。一个是前面提到的 Search+,应对及时的快速搜索足够,唯一的缺点不能像 Obsidian 那样折叠页面标题,这使得锁定搜索结果还是很费力。不过日期过滤对这个问题也有所缓解。
另一个是 Query Builder,可以设定更细致的搜索条件。不过,我常用的还是直接搜索“规范 情感”这样的多个关键词。这意味着将搜索同时出现“规范”和“情感”的块。Query Builder会根据设定的条件,展示满足这些块相关的要素,比如这些块的上一级块,或下一级的块,或所在的页面,或创建日期、修改日期。
相比 Search+, Query Builder的优势是能够直接展现页面列表,而不再之前那样在一堆块的结果中抓瞎,大概达到了 Obsidian 中的效果。缺点是没有搜索高亮。不过通过进一步的条件筛选,这不是太大的问题。
Obsidian
抛开其他问题,Obsidian 是非常理想的笔记软件。如前所述,它的检索功能十分强大和便利,远超 Roam。此外,它完全是本地化的,软件所处理的数据是纯文本。附件的管理也十分方面。它也提供页面引用功能,而这种功能其实是近年来笔记软件最重要的突破。
这些本地化的纯文本数据,经过精心组织和整理,将来接入 AI 技术也是非常容易的。现在已经出现一些实验性的项目。想一想,将来在 Obsidian 中通过 AI 模型挖局我们的笔记数据,与我们的笔记对话。这应该在未来的一两年内就会实现。
完全无需担心 Obsidian 的持久性问题。即使终止开发,我们仍然可以继续使用它。不像 Roam,无需任何登录操作就可以读取和操作笔记数据。使用 Obsidian 不会让我们产生类似 Roam 的焦虑和担忧。Obsidian 是能够让我们有信心使用十年甚至一辈子的笔记软件。
不过,Obsidian 只能提供极为有限的大纲编辑功能。以大纲方式编辑的文本,无法像Roam 那样方便的利用。主要的问题还是,在行与行之间没有空行,无论复制到普通 Markdown 编辑器中还是 Word 中,都不能正确识别段落。
如果你正在使用 Obsidian ,并且正在考虑 Roam,我的建议是,坚守前者。你可能不需要块引用功能,由此也无需承担可能的成本。现在,单纯记录和检索你的笔记,然后期待,将来 AI 技术在 Obsidian 中的实现。对于那些依赖大纲编辑器的人而言,比如我自己,则正在考虑将 Workflowy 作为我的主力大纲编辑器。经过检验,它非常稳定,超过了 Roam 和 Logseq。
Logseq
我很早就尝试 Logseq。这是一款 Roam 的劣质模仿品。相比 Roam,Logseq 的双链功能细节相当差。使用过的人应该很清楚这一点。Logseq 的软件开发有着严重的问题。首先,它的开发者不会管理软件开发。随着迭代更新,经常反复出现某些问题。一开始某些问题被修复了,但随着新的版本改动,它们又出现了。此外,原先本来好好的功能或特性,后来被无聊地修改成难用的东西。与其开发者沟通发现,他们在开发的过程中并没有想到要维持原有特性的稳定。这让人十分恼火。还有, Logseq 在设计新特性时,总是浅尝辄止。我曾在 Discord 写长文抱怨这些问题,但未见改观。整体来说,Logseq 的开发一直处于顾此失彼、缝缝补补的状态。单就是编辑器,直到最近才稳定下来。
不过,Logseq 的本地化数据设计要比 Roam 好。这使其与 Obsidian 更接近。如果将来 Logseq 停止更新,我们仍然可以继续使用软件并且保有我们的数据。将来如果 AI 技术发展,也有望在 Logseq 上利用。
然而,由于 Logseq 的开发者根本不会进行开发管理,使用 Logseq 的过程像是一种冒险历程。要知道,Logseq 的开发已经进入了第 5 个年头了。如今它还处于alpha阶段。这真的令人难以想象!至今,Logseq 都没有把一些功能固定和稳定下来,出一个稳定可用的版本,然后继续开发新功能和修复未知错误。
现在,我在Roam 中的数据已经完美迁移到 Logseq 。但只是将其作为某种备份。根据我以往的经验,只要深度使用 Logseq,就会遇到各种糟心的事情。
对于那些可以忍受以上提到的问题的人们来说,Logseq 是很有前景的一款笔记软件。仍然,我不推荐任何稍微有点头脑且有点脾气的人用 Logseq,因为 Logseq 的开发者真的毫无任何软件开发管理能力!
Workflowy
最后不得不提一下 Workflowy 。作为大纲笔记的祖师爷,在 Roam 之后,它其实并没有被超越。这两年积极开发了许多新的功能。Workflowy 依然简洁、优雅、强大,并且,看起来生命力远比 Roam 更强大。
我很欣赏 Workflowy 漂亮的看板。它可与大纲灵活转换。此外,就是它稳定的编辑器。现在,得益于新的导出功能,在 Workflowy 可以轻松撰写长文了。假使你依赖大纲编辑器,平时写材料在大纲编辑器中完成,然后又想在完成之后直接利用,那么现在可以考虑使用 Workflowy 了。它甚至比 Roam 还要好用,超越了市面上所有的大纲类笔记软件。
补充,目前 WorkFlowy 还是不支持直接转换成 Roam Research 那样的 flat markdown 文件导出。但通过编写脚本,能够实现。这对于依赖大纲编辑器来写作的人来说,非常重要。在了解可以自行编辑脚本之前,这一点是我转投 WorkFlowy 的一个重大阻碍。
import os
import sys
import re
def clean_roam_syntax_except_tag(text):
# 清除 Roam 块引用 ((uid))
text = re.sub(r"\(\([a-zA-Z0-9]{9}\)\)", "", text)
# 别名块引用 [别名](((uid))) → 别名
text = re.sub(r"\[\s*(.*?)\s*\]\(\(\([a-zA-Z0-9]{9}\)\)\)", r"\1", text)
# 模板变量 {{word-count}} 等
text = re.sub(r"\{\{.*?\}\}", "", text)
# 高亮 ^^text^^ → ==text==
text = re.sub(r"\^\^(.*?)\^\^", r"==\1==", text)
# 特殊倾斜 **text** → *text*
text = re.sub(r"__([^_]+?)__", r"*\1*", text)
# 页面引用 [[页面]] → 页面
text = re.sub(r"\[\[(.*?)\]\]", r"\1", text)
return text.strip()
def clean_roam_syntax_full(text):
# 首先删除所有行尾标签(包括多个标签的情况)
# 使用循环删除行尾的所有 #[[标签]] 格式
while True:
# 匹配行尾的标签(可能有前置空格)
new_text = re.sub(r"(.*?)\s*#\[\[[^\]]+\]\]\s*$", r"\1", text, flags=re.MULTILINE)
if new_text == text:
break
text = new_text
# 然后处理剩余的行中标签:#[[标签]] → 标签
text = re.sub(r"#\[\[(.+?)\]\]", r"\1", text)
# 最后清理除标签外的其他 Roam 语法
text = clean_roam_syntax_except_tag(text)
return text.strip()
def clean_tags_properly(text):
"""
专门处理标签的函数,按照正确的顺序处理
"""
# 1. 首先删除所有行尾标签(循环删除,处理多个标签的情况)
while True:
# 匹配行尾的 #[[标签]],可能有前置空格
new_text = re.sub(r"^(.*?)\s*#\[\[[^\]]+\]\]\s*$", r"\1", text, flags=re.MULTILINE)
if new_text == text:
break
text = new_text
# 2. 然后处理行中标签:#[[标签]] → 标签
text = re.sub(r"#\[\[(.+?)\]\]", r"\1", text)
return text
def flatten_lines(lines):
flattened = []
seen_first_nonlist_line = False
for line in lines:
if not line.strip():
continue # 跳过空行
leading_spaces = len(line) - len(line.lstrip())
stripped = line.lstrip()
if stripped.startswith("- "):
is_top_level = leading_spaces == 0
content = stripped[2:].strip()
# 行首标签处理:若以 #[[标签]] 开头,去除标签只留后文
content = re.sub(r"^#\[\[.+?\]\]\s+", "", content)
# 先处理标签(正确的顺序)
content = clean_tags_properly(content)
# 再处理其他 Roam 语法
content = clean_roam_syntax_except_tag(content)
# 第一层级加 ##
if is_top_level:
content = f"## {content}"
flattened.append(content)
flattened.append("") # 添加空行
else:
content = line.strip()
# 处理标签和其他语法
content = clean_tags_properly(content)
content = clean_roam_syntax_except_tag(content)
if not seen_first_nonlist_line:
content = f"# {content}"
seen_first_nonlist_line = True
flattened.append(content)
flattened.append("")
return flattened
def get_unique_output_path(base, ext):
output_path = base + "_flat" + ext
i = 1
while os.path.exists(output_path):
output_path = f"{base}_flat_{i}{ext}"
i += 1
return output_path
def process_file(input_path):
with open(input_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
flattened_lines = flatten_lines(lines)
base, ext = os.path.splitext(input_path)
output_path = get_unique_output_path(base, ext)
with open(output_path, 'w', encoding='utf-8') as f:
f.write('\n'.join(flattened_lines))
print(f"已处理:{os.path.basename(input_path)} → {os.path.basename(output_path)}")
def process_directory(folder_path):
for filename in os.listdir(folder_path):
if filename.endswith('.md'):
full_path = os.path.join(folder_path, filename)
process_file(full_path)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("用法: python3 flatten_roam_md.py <文件路径 或 目录路径>")
sys.exit(1)
path = sys.argv[1]
if os.path.isfile(path):
process_file(path)
elif os.path.isdir(path):
process_directory(path)
else:
print("无效路径,请提供一个 .md 文件或包含 .md 文件的目录")
使用方法可以问 AI。
此外,Workflowy 的搜索功能变得更加强大5。就文本搜索这一方面而言,检索特定关键词之后,Workflowy 只显示带有该关键词的节点,并且自动展开它们,无论它们本来是打开的还是收起的。若要调整搜索范围,只需要点击相应的节点之后再搜索。WorkFlowy 的搜索之所以如此强大,一个重要的原因在于,整个 WorkFlowy 知识库实际上就是一个单文件。WorkFlowy 的搜索体验与 Roam 简直可以说有云泥之别,甚至比 Obsidian 还要优雅。
总之,无论是记录还是检索,Workflowy 都不落后于市面上任何的笔记软件。
当然,Workflowy 本质上是一个 Web 程序。它没有本地化的数据,使用前必须登录。这始终有些令人不放心。
我仍考虑回归 Workflowy ,并且衷心推荐那些依赖大纲编辑器的朋友们尝试或者回归这款软件。只有一点,我们需要做好数据的备份。
WorkFlowy 已经开始内部测试 AI 功能,其基本的设想是,通过 AI 更好地回忆自己之前写下的东西。WorkFlowy 其实搜索已经是极致,对 AI 的需求并没有那么强烈,但这仍然令人期待。
Notion
其实 Notion 一直不在我的笔记候选之中,主要是因为我对任务管理的要求并不高。我更倾向于文本特性而不是 Notion 那样的数据库。但不得不说,Notion 真的很好用,对免费用户也很慷慨。AI 功能的引入,使我们能够与自己的知识库对话,这让 Notion 变得更加吸引人。
同样地,Notion 的缺点在于,非本地化,学习成本很高。
结语
我已经很久没有纠结和折腾新的笔记软件了。有许多新型笔记软件我在上面并没有提及,诸如 Heptabase、Tana 等等(甚至还可以说,包括Notion)。这是因为,出于接下来将要总结的理由,应该将它们与 Roam 做类似的考虑。
-
新型笔记软件的实质是一种新型电子玩具。6沉迷于新型笔记软件等“效率”工具,和沉迷于电子游戏没有区别。当今互联网三大电子玩具:效率工具、博客程序和电子游戏,今后如有机会我还会详细讨论。
-
记笔记的本质是记录和搜索。原则上,使用任何文本编辑器都能记笔记(OneNote例外,它的搜索功能是个废物)。新型笔记软件仅仅是使记笔记这件事提高了一点效率,增添了一些乐趣。一些新型笔记软件由于搜索功能孱弱,甚至会降低效率。
-
选择笔记软件应该考虑长远性。本地化、免费使用,是选择笔记软件时最重要的特性。选择一种软件就是选择一种方法和技术。无损迁移数据是不可能的。依照这个标准,不应该深度依赖 Workflowy、Notion、Roam 这样的程序。Obsidian 或 Logseq 则是相当不错的选项。如果依赖大纲编辑器,则选择 Logseq,否则,Obsidian 是最佳选择。
-
页面双链块双链更重要。页面双链颠覆了以文档为单位组织笔记的传统方式,而块引用的实际作用没有人们预想的那样大。假如坚持使用 Roam,请从现在开始,尽量减少使用块引用,这将为将来的迁移提供不少便利。
我仍在犹豫我的最终方案,并且仍把 Roam Research 作为我的主力软件。本来,我已经打算迁移至 WorkFlowy。但两个搜索插件似乎要留住我的脚步。
当然,如果实在纠结如何选择,不妨设想几个重要的维度,并为它们赋予不同的权重,然后给各个软件赋分,通过数字来清晰地看到最适合自己的选择。以下是我的一个示例:
| 维度 | 权重 | Obsidian | WorkFlowy | Roam Research | Notion |
|---|---|---|---|---|---|
| 本地化 | 5 | 1 | 0 | 0.7 | 0 |
| 搜索 | 8 | 0.7 | 1 | 0.4 ∆ | 0.5 |
| 大纲编辑器 | 7 | 0.2 | 1 | 1 | 0 |
| 任务管理 | 4 | 0.3 | 1 | 0.3 | 1 |
| 持续性 | 7 | 1 | 0.3 | 0.2 | 0.7 |
| 日常编辑利用 | 5 | 0.5 | 0.2 | 1 | 0.5 |
| 侧边栏对照 | 5 | 0.5 | 0 | 1 | 0.4 |
| 界面美观优雅度 | 6 | 0.1 | 1 | 0.6 | 0.7 |
| 双链笔记 | 2 | 1 | 0.2 | 1 | 0.2 |
| 可迁移性 | 4 | 1 | 0 | 0 | 0 |
| 资源管理 | 3 | 1 | 0 | 0.3 | 0.7 |
| AI 利用性 | 2 | 0.2 | 0.7 | 0.1 | 0.8 |
结果排名如下:
- Obsidian: 0.607 (35.2/58)
- Roam Research: 0.569 (33.0/58)
- WorkFlowy: 0.516 (29.9/58)
- Notion: 0.443 (25.7/58)
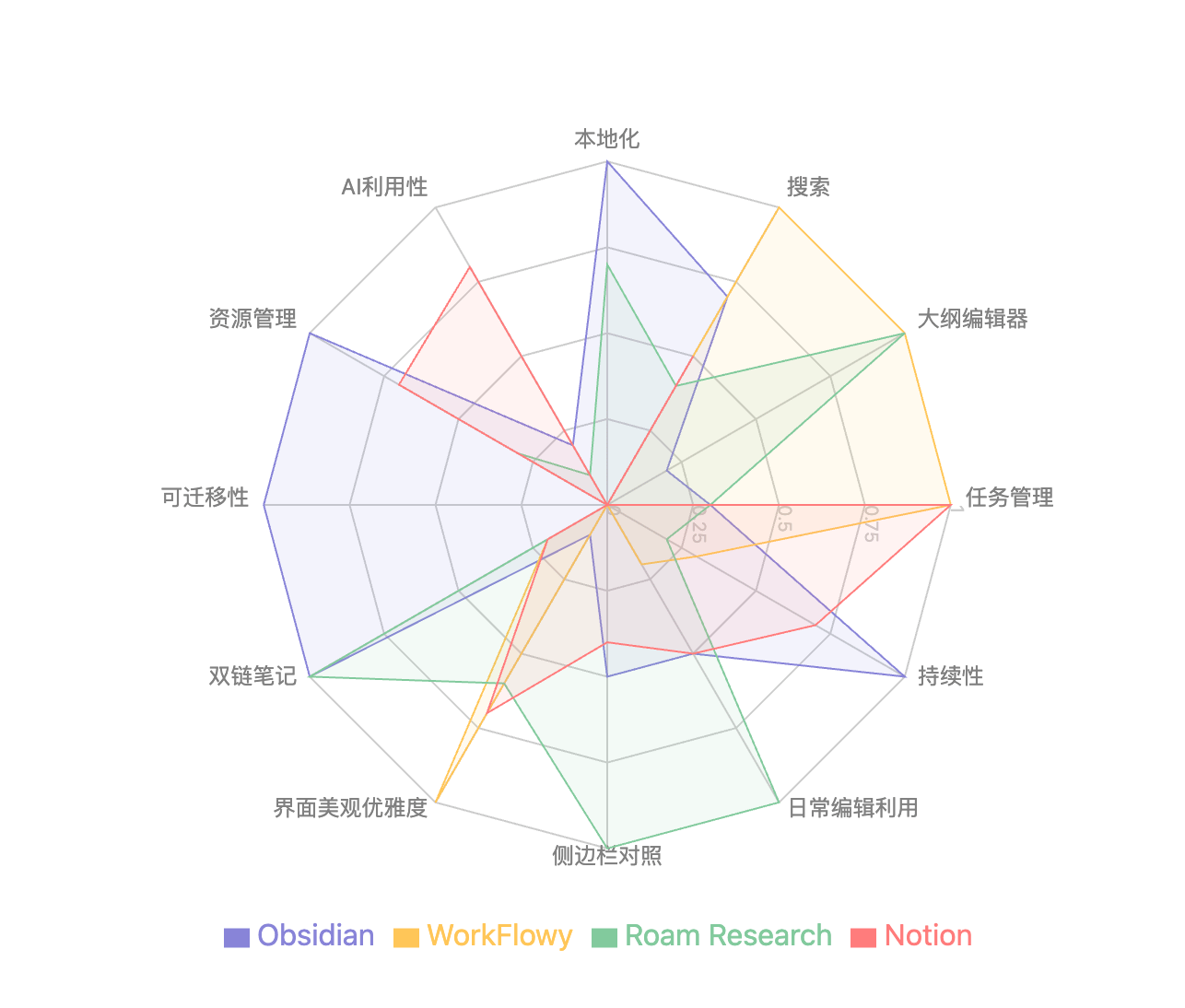
增加或调整不同维度参数,来改变软件的排名。但我们很容易看到,没有任何一款软件是全能的,纠结始终难以消除,我们只能有所偏重。
Footnotes
-
参见我的文章:毒品、博客、游戏与成瘾:基于个人经验的探讨 ↩
-
一些有关 Roam Research 的(唱衰)文章:The Fall of Roam, Why note-taking apps don’t make us smarter ;一个综述:Roam Research — What comes after a renaissance?。这是可预料的。的确,除了撰写+搜索模式的一般笔记软件之外。任何新型笔记软件都只会是少数人的玩具(这些人同时还玩各种新型电子游戏)。只是我希望在它真的陨落那天,Roam Research 能够允许人们继续在本地使用而无须登录。 ↩