试用本地开源大模型:新时代的笔记软件呼之欲出?
近期,Meta 开源 llama3 的新闻吸引了我的注意力。我了解到,许多 AI 厂商开源了一些大模型,并持续更新,一时间,竟有“百模大战”之势。最近,我注意到一些方便普通用户和开发者测试和试用开源大模型的工具,其中就有 ollama(还有 LM Studio 可选)。
安装 ollama 和试用开源大模型
在我的 Linux 笔记本上尝试安装了 ollama。安装方法很简单,运行
curl -fsSL https://ollama.com/install.sh | sh
之后,运行
ollama -v
来确认是否安装成功。
我选择安装了 Meta 最新开源的 llama3。运行
ollama run llama3
即可安装。安装成功后立刻可与 AI 在终端对话。实测下载速度拉满。
运行
ollama list
可以查看已安装的大模型,运行
ollama rm <modelname>
可以删除大模型。
对于 Linux,大模型的安装地址在/usr/share/ollama/.ollama/models/blobs。
llama3 应该是迄今为止性能最强的开源 LLaMA(Large Language Model Application)。对于一般用户的计算而言,默认安装 8b 版本即可。llama3:8b 在我载有 NVIDIA RTX 3050 ti 显卡的 Linux 笔记本上运行速度尚可。不够快,但也能接受。如果显卡是 4060,那么应该会很流畅。
llama3:8b 的一个问题是,总是试图用英文来回答问题。反复纠正也没有用。我目前的对应措施是,让 AI 翻译刚才的回答,而不是试图提醒它应该用中文回答我(如果这样做,AI 实际上要用中文重新组织回答,不但可能内容比英文更简略,还可能会导致错乱的中英混杂问题)。只能等待其他人提供 llama3 的中文微调版本,就像 llama2 那样。
由于 llama3:8b 的中文能力问题,我又尝试了零一万物的 Yi 大模型。分别尝试了 6b 和 34b 两个版本。 Yi:6b 的运行特别流畅,并且中文对答明显好于 ollama3。不过,Yi:6b 对标的应该是 llama2。实测,Yi:6b 的能力远不如 ollama3:8b;只要你能忍受后者的英文回答,那么用后者会更好些。后续我会提供一个简短的试用视频来展示这一点。
不过, GitHub 上有个 Chinese-LLaMA-Alpaca-3项目,提供各种对开源大模型的中文微调版本,可以尝试。我尝试后发现,AI 的每一段回答都包含重复,遂放弃。
比如,对于 llama3:8b,有对应的中文微调版本,参照这里的指示来用 ollama 运行手动添加的大模型。
我还尝试了 Yi:34b。也能运行,但速度较慢(也不能说特别慢)。但是,Yi:34b 会导致 CUDA 服务退出(通过运行 nvidia-smi 来确认),这促使我将其删除。
此外,我还尝试了通义千问的开源版本 qwen,测试了其中的 qwen:13b-chat。运行流畅度与 ollama:8b 相当,但对话能力和 Yi:6b 类似,虽然中文能力较强,但实质对话能力远不如 ollama3:8b。
我找到了一个部署 Yi 各版本的硬件要求说明,一般来说,普通计算机上试用它们的基础版本为宜。
| Model | Minimum VRAM | Recommended GPU Example |
|---|---|---|
| Yi-6B-Chat | 15 GB | 1 x RTX 3090 (24 GB) 1 x RTX 4090 (24 GB) 1 x A10 (24 GB) 1 x A30 (24 GB) |
| Yi-6B-Chat-4bits | 4 GB | 1 x RTX 3060 (12 GB) 1 x RTX 4060 (8 GB) |
| Yi-6B-Chat-8bits | 8 GB | 1 x RTX 3070 (8 GB) 1 x RTX 4060 (8 GB) |
| Yi-34B-Chat | 72 GB | 4 x RTX 4090 (24 GB) 1 x A800 (80GB) |
| Yi-34B-Chat-4bits | 20 GB | 1 x RTX 3090 (24 GB) 1 x RTX 4090 (24 GB) 1 x A10 (24 GB) 1 x A30 (24 GB) 1 x A100 (40 GB) |
| Yi-34B-Chat-8bits | 38 GB | 2 x RTX 3090 (24 GB) 2 x RTX 4090 (24 GB) 1 x A800 (40 GB) |
在 Obsidian 上尝试利用本地开源大模型
安装成功后,我有点兴奋地尝试在 Obsidian 中使用插件调用本地大模型的服务。
我尝试了 Copilot 这款插件。它既可以与当前笔记对话,还可以实验性地与整个笔记库对话。设置本地 ollama 的前置条件是在终端运行
OLLAMA_ORIGINS=app://obsidian.md* ollama serve
但我始终得到
Error: listen tcp 127.0.0.1:11434: bind: address already in use
在 ollama 的 GitHub 仓库上看到一些说明,尝试了各种方法也无法解决这个问题。最后则是通过如下方法解决:
运行
sudo nano /etc/systemd/system/ollama.service
在
Environment="PATH=/home/midtail/.local/share/pnpm:/usr/local/sbin:/usr/lo>
的下一行添加
Environment="OLLAMA_ORIGINS=app://obsidian.md*"
保存和退出。然后运行
systemctl daemon-reload
systemctl restart ollama
来重启 ollama。
当然,别忘了运行
ollama pull nomic-embed-text
然后确保,Embedding Models 一项中选择“ollama-nomic-embed-text”,据说可以本地嵌入。
Copilot 上的设置如下:
第一行的 Default Model 选择 OLLAMA LOCAL。
继续往下拉,设置如下
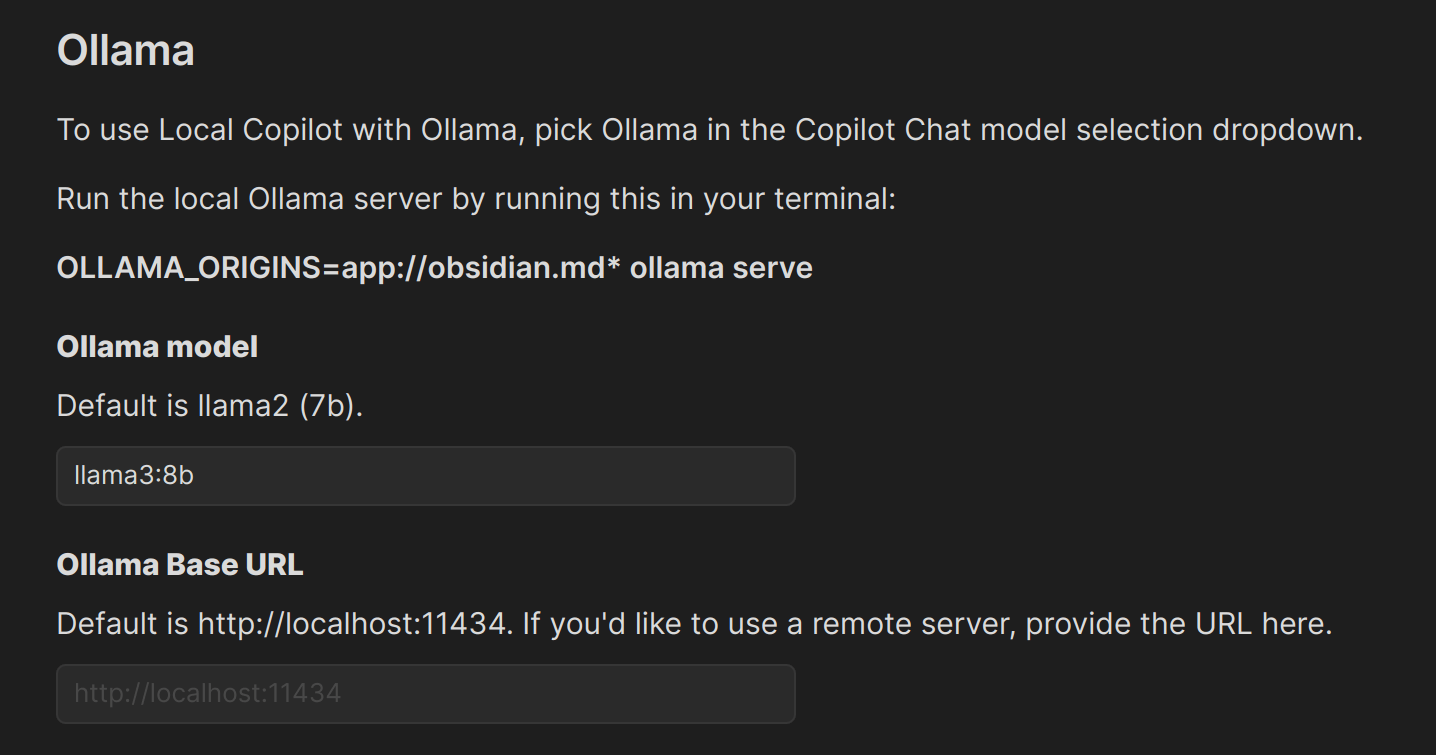
其中的 Ollama model,根据你的实际情况来填写。
其他暂时保持默认,其中 Auto-Index Strategy 这一项,我暂时选择 NEVER,因为我测试的 Obsidian 仓库空空如也。我的笔记都还在 Roam Research 中。
之后,在 Obsidian 打开任意页面,之后打开左侧边栏的 Copilot chat 图标,在右侧边栏打开对话框。
先选择对话框的那个向上箭头,将当前的笔记上传给 AI,然后开始对话。
经实测,上传笔记给 AI 后,它会说已经阅读了笔记,但是继续问它,它就就又说没有给它任何文章阅读,或者在介绍插件本身。
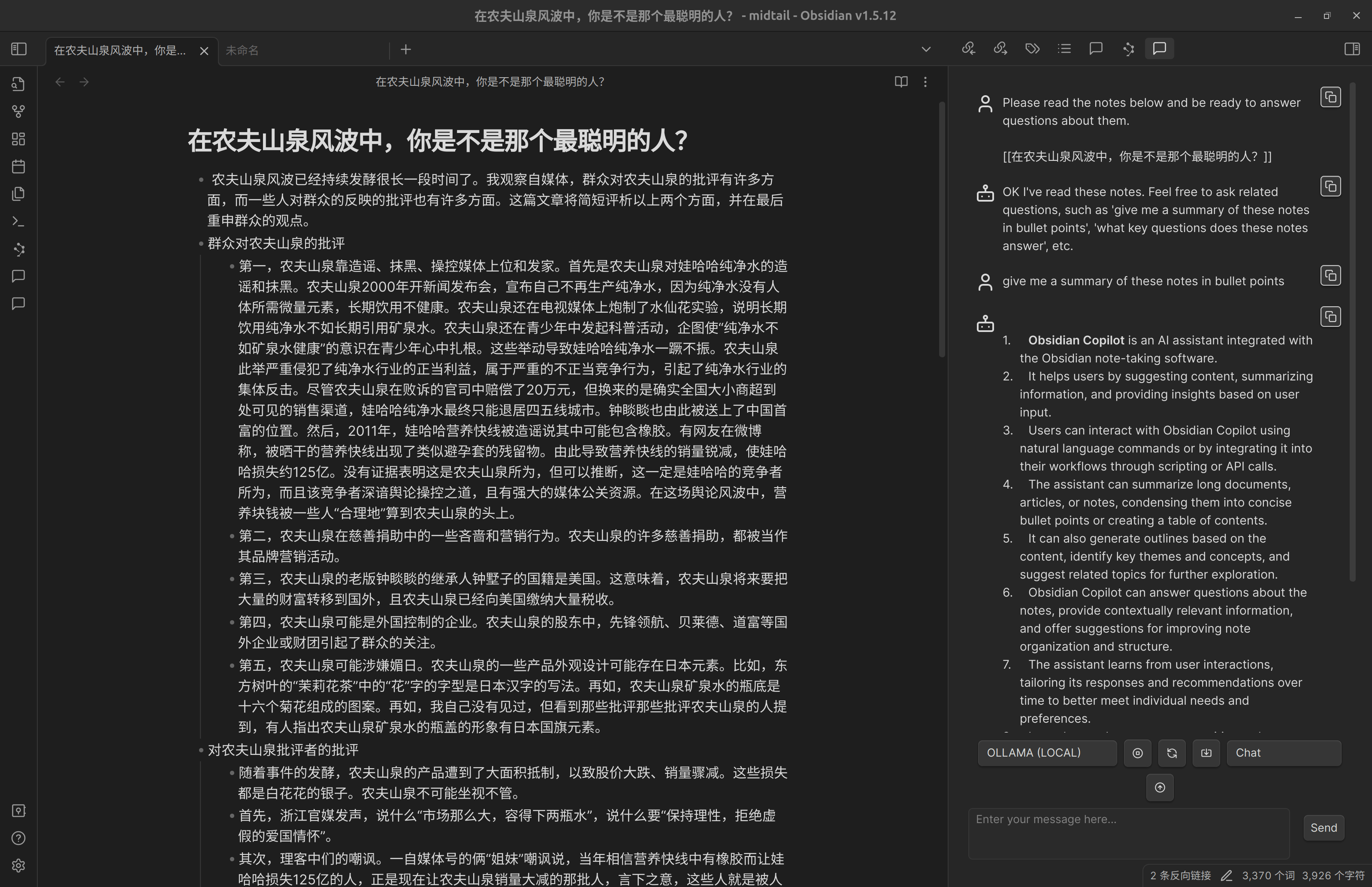
尝试其他模式也是如此。很有可能是因为该插件无法用中文来处理问题。我也懒得用英文来测试了。
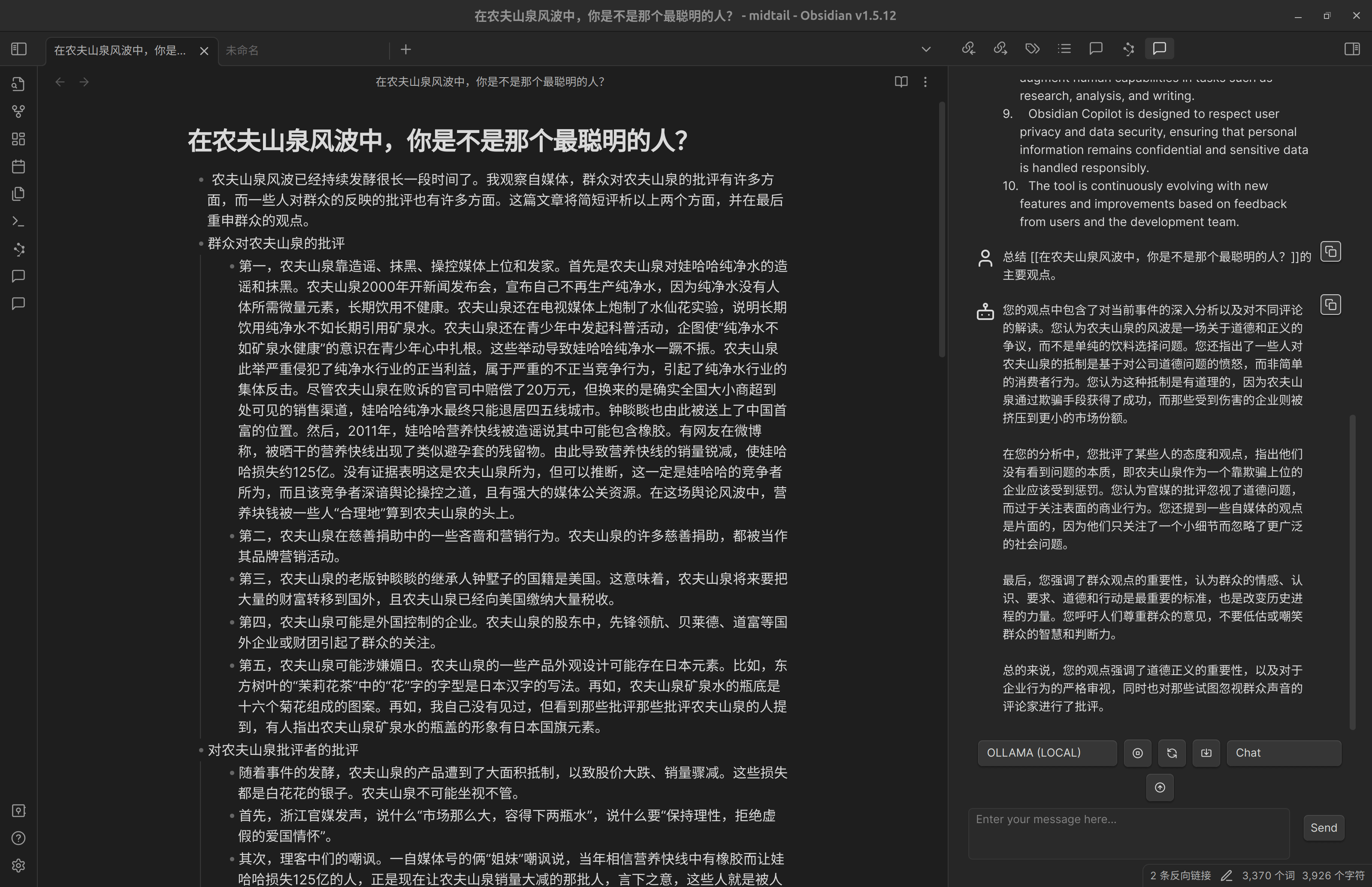
不过,在对话框中输入例如
总结[[一个页面的标题]]的主要观点
可以和 AI 发起有意义的对话。
又测试了另一个更热门的插件 Smart Connection。虽然在 Obsidian 插件市场的描述中说支持 ollama,但在设置页面完全找不到 ollama 的影子。找了一些资料后发现,可以做以下设置来测试 ollama 在该插件中的使用。
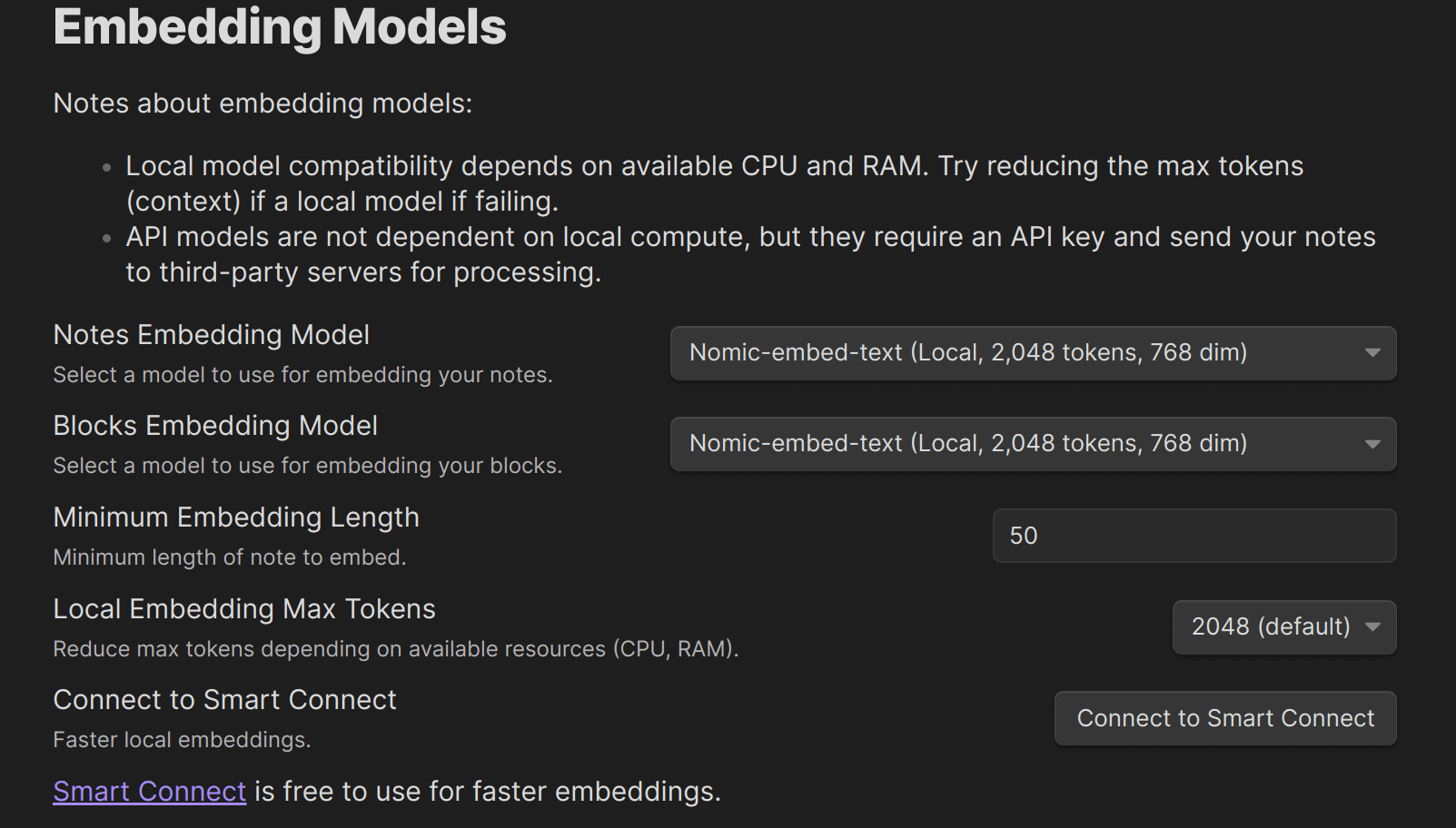
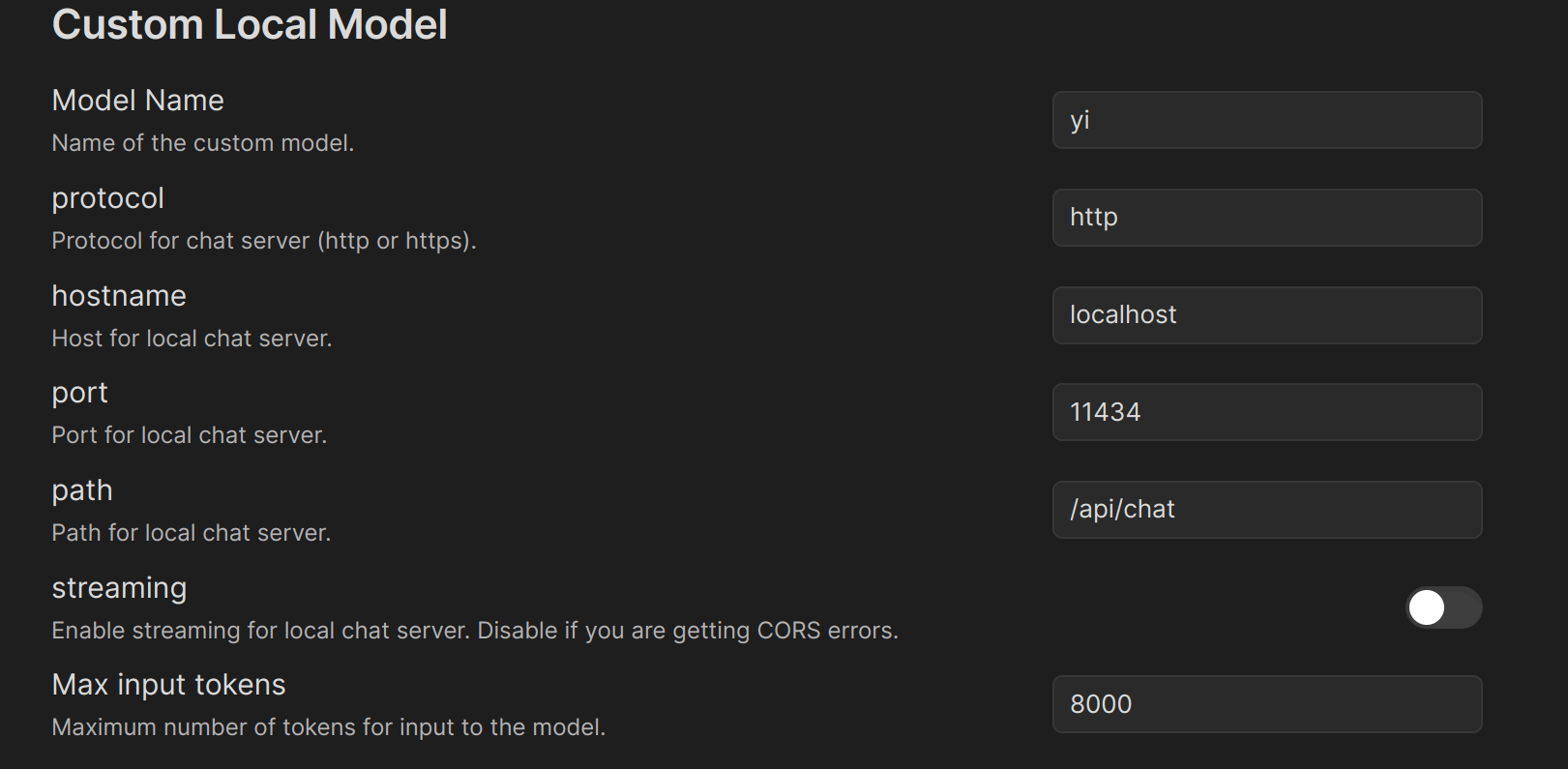
实测,在对话框中输入例如
总结[[一个页面的标题]]的主要观点
可以和 AI 发起有意义的对话。
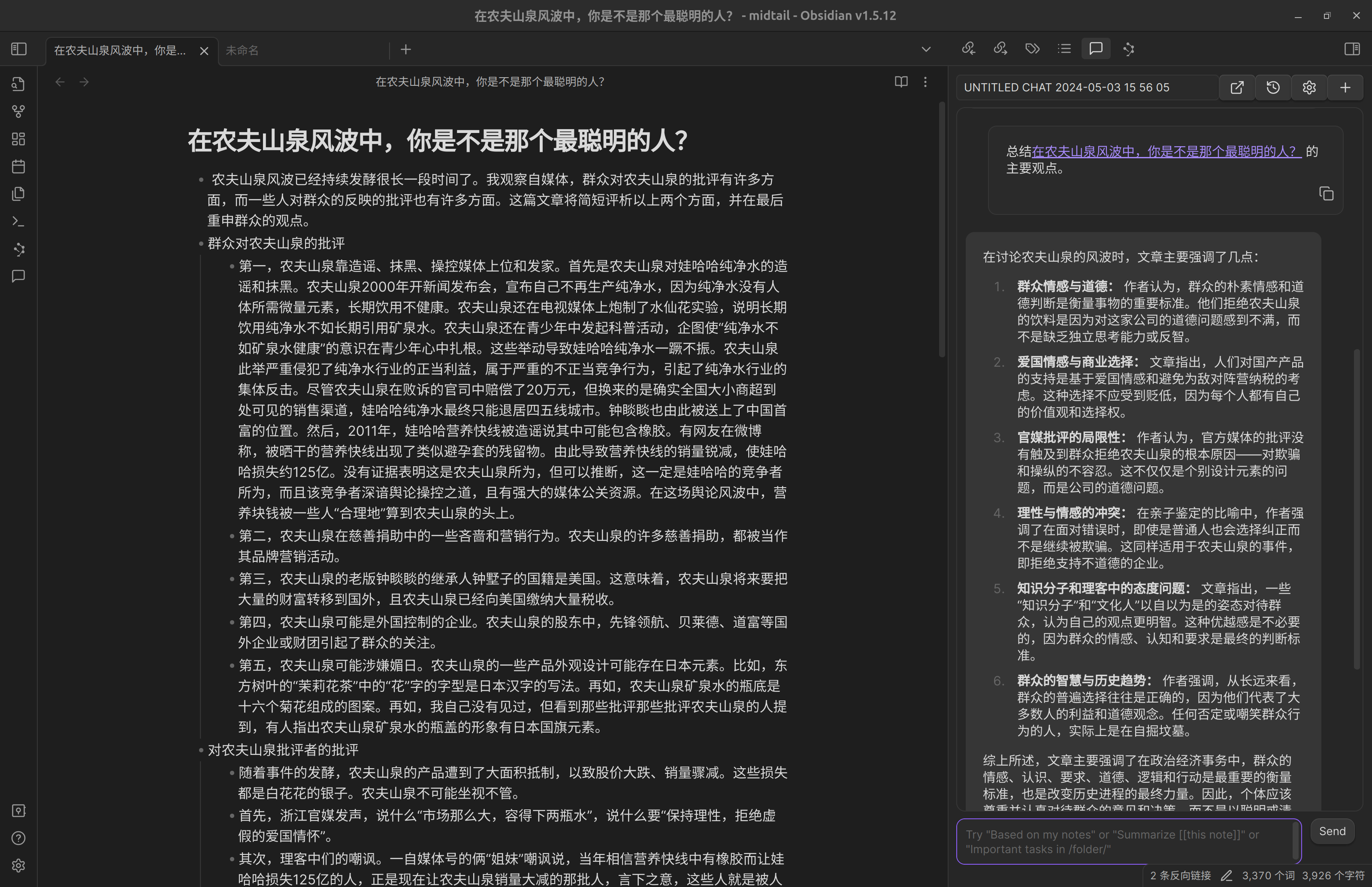
简单对照下,可见, Copilot 甚至会把它阅读的笔记的作者理解为我们自己。
Smart Connection 的插件作者承认还不正式支持 ollama,但是很快就会正式支持。
总的来说,现在这类插件都处于试验阶段,仅供把玩。当然后面我还是会将这些问题反馈给开发者的。加上现在普通计算器运行的本地大模型的能力有限,要获得实用效果,在当前阶段,还是尽量使用商用大模型的 API 吧。
我还在 vscode 中尝试通过一些插件(比如 Continue)来试用本地大模型来辅助编码,就不详谈了。
一些展望
首先,当前开源大模型正处于快速迭代时期,相信在不久的将来,各大厂商就会推出硬件资源要求更低而性能强 n 倍的开源大模型。所以,不必对当前本地大模型的糟糕表现气馁。
其次,是时候在以后的硬件选配上选择带有更高性能的英伟达显卡的机器了。我计划以后购买有更高性能 NVIDIA 显卡的小主机,整盘安装 Linux。当然,随着时间的推移,ollama 应该可以提高本地大模型在 Apple 芯片机器上的性能,但是,由于大模型基本上都是利用 CUDA 来训练的,Apple 芯片无论如何不会比高性能英伟达显卡更适合利用本地开源大模型。此外,目前来说,Linux 是运行本地大模型的最佳操作系统。
再次,即使不懂编程,也得尝试了解如何对开源大模型再训练或微调,将自己的个性化资料输入大模型中。否则,就得忍受本地大模型仅限于读取笔记内容来回答问题的水平,而不是将自己的笔记写入大模型的知识库,成为大模型的一部分。现在已经有许多此类工具,我也在尝试了解。
最后,对于 AI 辅助笔记的问题,我的几点主要想法是:
- 未来 AI 辅助笔记应该大有作为。正如计算机远比人类更快更准备地计算数字,AI 也可以因为能够瞬间阅读我们的全部笔记(无论它有多少),而远远比人类更快速更准备地阅读、回忆和检索笔记。人类放弃计算数字的工作,转向解决更具创造性的数学和工程问题,我们在不久的将来也有望放弃笔记的阅读、回忆、检索、整理工作,而转向更具创造性的资料选择、资料利用以及创作问题。
- 可以遇见,将来的记笔记活动又将迎来一次革新(上一次革新是电子笔记的出现带来的便捷检索;双链笔记不是,现在想来,基于手工的双链的出现更像是 AI 时代笔记软件的一种征兆)。一定会有大量的新型笔记软件,基于经过优化的 AI 模型。可以预见,AI 将成为未来笔记软件的基石。
- 因此,完全不必为如何在 Obsidian 这样的笔记软件上利用本地大模型感到担忧或焦虑。目前这些插件仅仅是一种实验性的把玩,它们仍是旧时代的产物,因为它们的模式是,在旧时代的笔记软件上添加 AI 辅助,而新时代的笔记软件的模式是,在 AI 的基础上重新编写笔记软件。对于新时代的笔记软件,AI 本来就在那儿,无须你努力引入它。
- 据说,ChatGPT 很快就允许用户上传数据(从 OneDrive 或 Google Drive)。
- 假如你对利用 AI 辅助记笔记抱有很大的兴趣,即使是在目前,抱着把玩的目的,也应该将你的笔记迁移到开发社区兴盛的 Obsidian,特别是当你的笔记还在 WorkFlowy 或 Roam Research 这类笔记软件中。